Dê-me uma alavanca e um ponto de apoio e levantarei o mundo
Arquimedes
Olá comunidade, nessa série de posts vamos mostrar um pouco do aprendizado que tivemos em configurar o Airflow para a utilização dos nós virtuais no Azure no escalonamento automático de tarefas do Airflow. Nesse primeiro post vamos justificar a escolha do Airflow utilizando o KubernetsPodOperator no desenvolvimento de ETLs e modelos matemáticos e as vantagens da centralização dos processos de DS em uma única arquitetura baseada em Python/Docker.
Sobre Airflow
Airflow é um gerenciador de tarefas muito utilizado no mercado, ele nasceu como um projeto interno do Airbnb com o objetivo de criar, agendar e monitorar de forma programática fluxos de trabalho. Uma das vantagens do Airflow é que as dags são escritas em Python, o que facilita o uso por cientistas de dados (comumente proficientes nesta linguagem) e o versionamento utilizando o git.
Hoje o Airflow é um projeto aberto associado à fundação Apache. Entre suas diversas vantagens ele apresenta diversas conexões com banco de dados, linguagens de programação e ferramentas de comunicação como o Telegram e o Slack. Entretanto a principal crítica a sua utilização é o escalonamento, a VM/Cluster que roda o Airflow tem que ficar “em pé” o tempo todo aumentando o custo de infraestrutura do projeto.
O Airflow apresenta diferentes tipos de executors, eles configuram como as tarefas são executadas. Em suas configurações mais simples, as tarefas são rodadas na mesma VM que o Airflow é servido isso faz com que, caso existam tarefas que necessitam de um poder computacional maior, há um custo fixo alto de infraestrutura. Com a utilização do Celery Executor é possível rodas as tarefas em processos worker com a comunicação através de uma mensageria como o RabbitMQ, isso permite a paralelização das tarefas e desacopla sua execução do ambiente webserver.
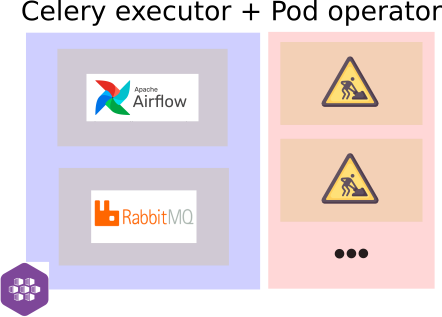
Mesmo com a utilização do Celery, apesar de ser possível separar o webserver da execução das tarefas em diferentes VMs (quando falar de VMs entenda também containers), é necessário manter as VMs das tarefas ligadas o que mantém o problema do custo fixo. Para solucionar isso utilizamos uma combinação do Celery Executor com o KubernetsPodOperator, dessa forma é mantido um processo fixo de tamanho pequeno e os processos mais “pesados” são rodados em um nó virtual no Azure Kubernets Service provisionando automaticamente o poder computacional requisitado.

Sobre Kubernets
Acredito que hoje o Kubernets seja o principal orquestrador de containers a ser utilizado pelo mercado. Nasceu inicialmente como um projeto interno do Google, mas foi disponibilizado para a comunidade e encontra-se disponível como serviço nas principais nuvens (AWS, GCP, Azure, etc…). Ele permite o deploy de containers Docker em um ambiente distribuído (escalonamento horizontal), tratando de forma nativa a distribuição de cargas entre os containers de um mesmo tipo, permitindo montar diferentes formas de armazenamento e criação de load balancers externo para expor as APIs… só falta fazer café, mas dizem que essa feature estará prevista para a versão 2.0.
A utilização de containers Docker no deploy de aplicações permite a definição do ambiente completo que será utilizado nos containers. Isso reduz bastante o problema de “mas roda na minha máquina” e permite o versionamento através das imagens facilitando o roll-back no caso das coisas darem ruim com a nova versão.
Sobre DS e a tarefa hercúlia de Pokemon Go
Ser um cientista de dados não é algo fácil, cada semana aparece um bixinho novo para ser incorporado ao stack de desenvolvimento… fora isso cada nuvem implementa soluções similares, mas cada uma com a sua particularidade (Sagemaker, ML-Studio, Vertex AI). Assim algo que a principio deveria reduzir a complexidade na criação e deploy de modelos, se torna rapidamente em um hell de incompatibilidade de dependências e diferentes formas de acesso, UX e APIs.

Fora isso, muitas vezes algumas ferramentas baseadas em Spark como o Databricks e o Glue são utilizadas para fazer a busca inicial dos dados e logo em seguida é usado o toPandas. Rodar modelos ou implementar feature enginering usando a API Spark não é fácil para um cientista de dados padrão e converter para Python nativo faz com que o nó worker seja um gasto de dinheiro.
Nesses serviços ainda é necessário instalar todas as dependências no inicio de cada job o que é novamente um gasto de dinheiro, isso em um ambiente que não é muito transparente (OS pacotes, pré-instalados, …) podendo levar incompatibilidade por versão do Python ou pela necessidade de pacotes não Python como o libglpk-dev usado para otimização linear. Na minha opinião esses ambiente acabam sendo uma forma de deploy muito utilizada pela falta de conhecimento de outras ferramentas para códigos em python com provisionamento automático e pela facilidade da utilização de notebooks (que são péssimos a longo prazo), apesar de serem extremamente úteis em muitos casos principalmente na utilização de Spark (não briga comigo só pq você ama um notebook Júpiter!).
Como diria Arquimedes, me dê um cluster Kubernets e uns discos e moverei o mundo (ou algo similar no contexto da época). Basicamente com containers é possível fazer o deploy de qualquer coisa: dá para fazer o deploy de um banco de dados Postgres e um RabbitMQ usando o mesmo cluster que posteriormente pode ser utilizado para servir uma API em Flask e um modelo em R rodando em batch uma vez ao dia, dá até para subir um cluster Spark se quiser. A nossa proposta é centralizar o desenvolvimento em uma única arquitetura, dessa forma tanto cientistas de dados quanto desenvolvedores de sistemas podem conversar entre si se apoiando mutuamente na construção de valor para o negócio como um todo.
A proposta
Nossa proposta é centralizar todo o processo de Data Science na utilização de imagens Docker responsáveis pelo data prep, estimação dos modelos e previsão usando códigos Python. Tais imagens seriam simples conteriam todos os pacotes necessários tanto Linux como Python centralizando todas as dependências OS/Python. Dessa forma os modelos poderiam ser versionados no repositório de imagens de forma separada, o que no futuro poderia permitir processos de CI/CD. As imagens seriam utilizadas nos KubernetsPodOperator no Airflow, sendo a execução direcionada para o nó virtual permitindo o escalonamento automático para a execução das tasks.
Dessa forma o stack seria reduzido apenas à Python + Docker + Python. Não somos contra os serviços de Spark e outros serviços gerenciados, eles podem ser utilizados em casos específicos caso tragam vantagens reais… aqui acho que vale a regra mais importante da programação: keep it simple, keep it stupid (ou algo do tipo).

Próximos posts
Nos próximos posts vamos descer no detalhe da implantação da arquitetura proposta, começando pelo provisionamento do cluster com nós virtuais utilizando o Azure. Posteriormente descreveremos a implantação do Airflow + RabbitMQ + Postgres no Kubernets com a descrição dos arquivos yml necessário para que o treco funcione adequadamente, isso deu um bom trabalho para falar a verdade. Tem um tal de Helm que dá para usar para fazer os deploys, mas pelo principio da redução da diversidade de Pokemons, optamos por usar os yml mesmo (ainda não me entendi muito bem com ele na verdade).
Nos vemos em breve cowboys do espaço!