Science is fun. Science is curiosity. We all have natural curiosity. Science is a process of investigating. It’s posing questions and coming up with a method. It’s delving in.
Sally Ride (1951, 2012)
Astronauta America e Física 1a Mulher americana no espaço
Olá comunidade,
Nós da Murabei trabalhamos com microserviços já a algum tempo (K8s early adopter, só para nos gabar um pouco…). Internamente desenvolvemos uma ferramenta para Data Science chamada Pumpwood que pode ser facilmente estendida utilizando novos serviço, adicionando/removendo funcionalidades caso necessário. O problema é que a arquitetura em microserviços/domínios traz algumas dificuldades principalmente para o consumo das informações pelas ferramentas de BI.
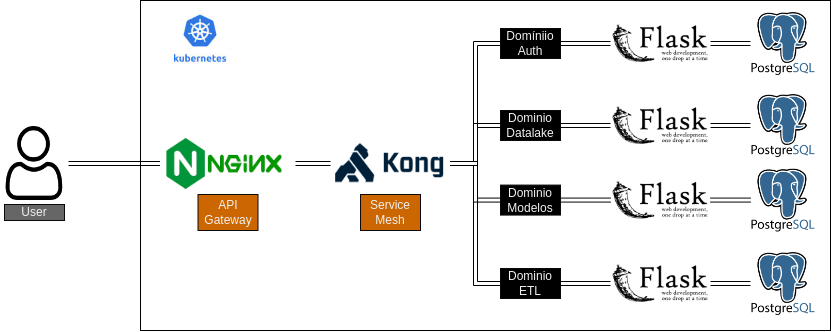
Como cada domínio possui seu próprio banco de dados dedicado, as informações da aplicação ficam dispersas. Em um exemplo disso, o modelo matemático criado no “Domínio Modelos” apresenta um campo created_by_id correspondente ao usuário responsável pela criação do modelo, esta dimensão encontra-se dentro do “Domínio Auth”; a mesma coisa acontece para os dados que são utilizados nos modelos que as dimensões encontram-se no banco de dados do “Domínio Datalake”.
Para a geração de dashboards é possível usar o PowerBI, mas como os dados encontram-se em fontes diferentes é necessário baixar os dados para o cache sendo impossível aplicar direct query nesse caso. Para o Metabase nem essa solução é possível, isso porque os dashboard são construídos diretamente dos resultados da query sobre uma única fonte e não é possível fazer query entre base de dados.
No Postgres em específico não é possível fazer queries entre bases de dados que estejam em um mesmo servidor… então colocar todos os dados em um servidor separados por base de dados também não funcionaria; nós nos recusamos a pensar em colocar dados de diferentes domínios separados por schemas ou empilhados em uma mesma base de dados/schema separados por um sufixo nas tabelas (datalake__[nome da tabela]), até gabiarra tem seus limites!
[espaço para um giff sobre gambiarra, mas “gambiarra” é um termo tão brasileiro que buscar por “work around” não chega aos pés do conceito]
Para conseguir seguir em frente, amarramos no arame e durepox e inicialmente construímos um banco de dados para gerar os dashboards. Este seria alimentado por um processo assíncrono responsável por ler as informações de cada banco de dados e salva-las no banco de dados de dasboard já no formato star schema.
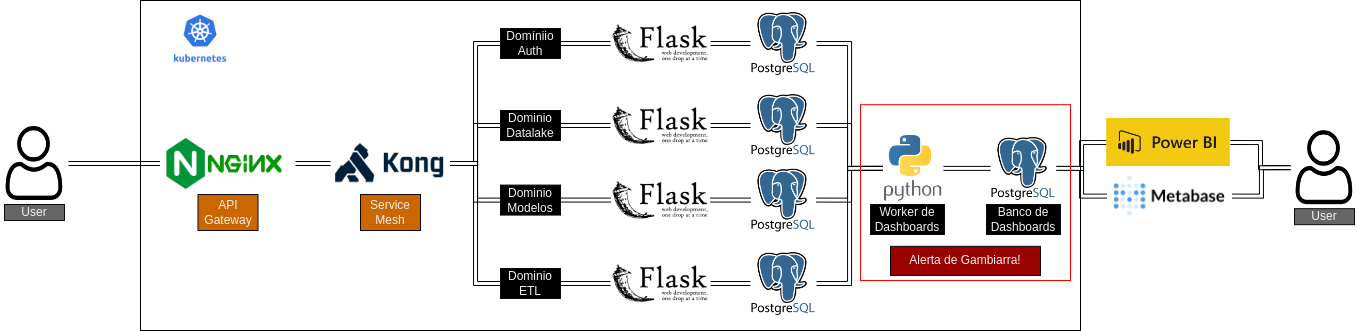
Bom… isso é uma solução, mas com certeza não é uma boa solução! As dados ficam duplicados podendo ter inconsistências e os resultados demoram para aparecer para o usuário, sendo necessário que o processo worker de dashboard termine de rodar para que isso ocorra. Mas fora esse grande durepox com arame que foi a solução inicial, buscamos algo que fosse mais robusto e nessa busca encontramos o TrinoDB.

Um pouco sobre o Trino DB
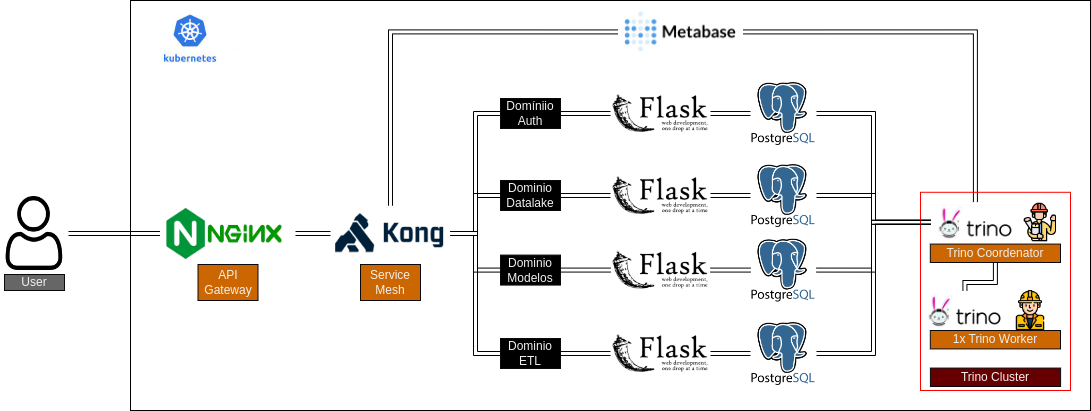
Trino DB é uma fork do Presto DB que por sua vez foi desenvolvido dentro do Facebook e disponibilizado como OpenSource através da Apache Foundation. Mais ou menos ele tem o mesmo papel que Kong/Istio tem para os microserviços só que os bancos de dados. Ele permite que todas as bases sejam buscada em um único lugar e o mais impressionante ainda permite o JOIN entre bases de dados de diferentes origens. Quando falo de diferentes origem digo, Postgres , SQLServer, MySQL, arquivos parquer, csv, JSON, Excel, mais um monte de outras! Na minha opinião o negócio é meio mágico, porque além de permitir fazer as query entre os dados de diferentes fontes, ainda otimiza o tratamento de grande volumes paralelizando e dividindo a query original.
O Trino é estruturado como um cluster de máquinas/containers sendo que necessariamente deve existir um nó coordenador e um ou mais nós worker. O nó coordenador é responsável por dividir as tarefas nos nós worker para a execução da query sendo também o ponto de contato como o cliente. Usando o Kubernets é possível trabalhar com o escalonamento automático dos nós worker caso o custo computacional da query esteja muito alto.
O Trino hoje é oferecido como uma solução SAS através do Starburst, mas é possível fazer o deploy utilizando a imagem Docker official disponibilizada pelo própria Starburst. Trino também esta por trás da solução Athena da AWS, normalmente quem usa gosta pela facilidade de ler os dados a partir das fontes originais.
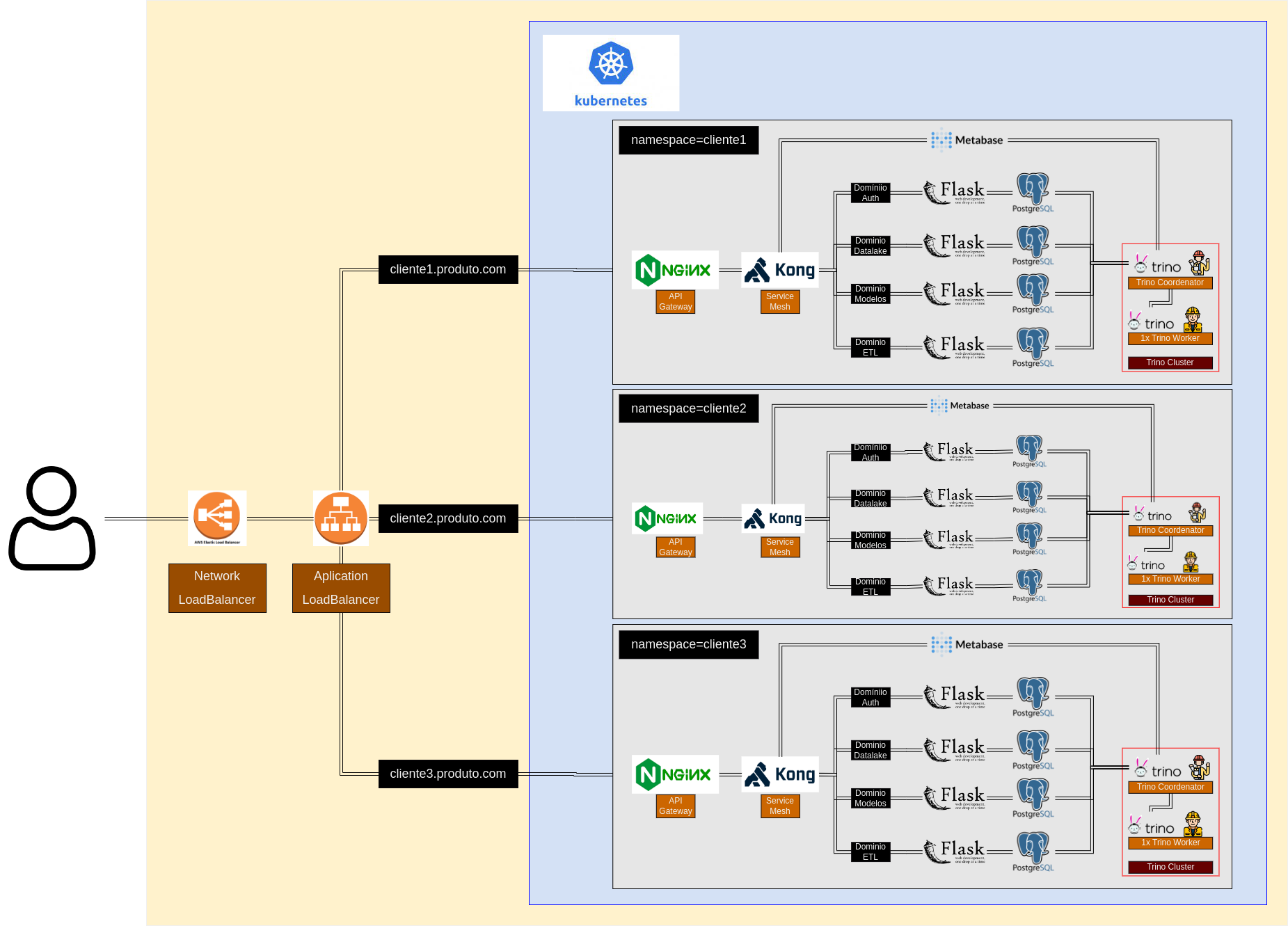
Na maioria dos casos faz mais sentido usar uma solução gerenciada seja a Stardurst ou mesmo o Athena, mas no nosso em específico estamos trabalhando em um produto que cada cliente vai ter seu ambiente apartado (sem mistura das informações), o que é permitido pela utilização do Kubenets e divisão através de namespaces.
No caso deste projeto que estamos trabalhando os clientes usarão (estamos em dev. ainda) a mesma infraestrutura computacional (o deploy será feito em um único cluster Kubernets), mas todos os dados e containers serão apartados através da divisão por namespaces e discos individualizados. Para fazer a distribuição nos diferentes namespaces utilizamos uma combinação do Application Load Balancer e Network Load Balacer da AWS de forma que cada um dos subdomínios (cliente1.produto.com, cliente2.produto.com) seja corretamente direcionado para seu namespace correspondente, isso tudo configurado através de manifestos de ingress no K8s (ok… já estamos passando dos limites da humildade).
Como não gostaríamos de ter um ponto único de acesso para os dados de todos os clientes (poderia causar vazamento de dados de um cliente para outro por erro de configuração), decidimos fazer o deploy do Trino em cada namespace com uma configuração pequena sendo apenas um nó coordenador e um nó worker.
Sobre deploy e imagens que foram criadas
Para facilitar o deploy foram criadas imagens Docker para o coordinator e para os nós worker do Trino. Estas imagens apresentam algumas características que facilitam sua utilização:
Arquivo zip com o catálogo de dados
O catalogo de dados que deve ser montado na pasta /etc/trino/catalog/ pode ser passado como um arquivo zip para o caminho /catalog/catalog.zip. Ao iniciar o container esse arquivo é descompactado e colocado na pasta correta.
Ajuste do ownership para a pasta Trino
Antes de iniciar o processo do Trino /etc/trino o ownership das pastas é ajustado para não ter problemas de acessos. Isso principalmente na montagem dos dados dentro dos containers costumam ser colocados com owner o root sendo que o Trino roda com o usuário trino.
Automaticamente cria um UUID para cada um dos nós Worker
Ao iniciar o container dos nós Worker automaticamente cria um UUID único para a identificação do nó no cluster Trino.
Exemplo de deploy usando o docker-compose
Utilizando as imagens criadas fica bem fácil fazer o deploy do cluster Trino e adicionar um número arbitrário de processos worker. Para fazer o deploy começamos construindo o catálogo de dados:
Na parte do catálogo de dados tem alguns macetizinhos aqui que a gente demorou para entender:
- 1o sobre a questão de segurança: Como o deploy do Trino será feito no mesmo namespace que contem os bancos de dados não é necessário expor os bancos para fora do cluster; como o deploy do trino também é feito no mesmo namespace do Metabase, também não é necessário expor o trino para o fora do cluster para a criação dos dashboards. Achamos isso uma vantagem de segurança…
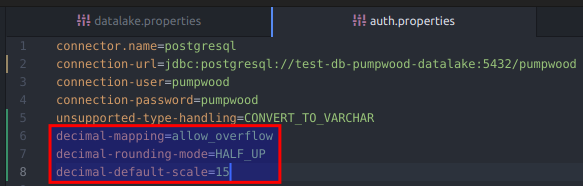
- 2a coisa… no caso estamos mapeando bancos de dados Postgres para dentro do Trino. O que acontece é que o Trino não consegue mapear campos do tipo Numeric com precisão arbitrária (funciona como um Decimal). Para que isso ocorra é necessário especificar para o Trino até onde tem que ser a precisão desse campo, se você não fizer isso e também não utilizar a opção
unsupported-type-handling=CONVERT_TO_VARCHARo campo nem vai aparecer no SELECT e você vai ficar doidinho quase abrindo o códigos do Trino para entender o que está acontecendo. Para indicar até quando tem que fazer o arredondamento do campo é possível usar as opçõesdecimal-mapping,decimal-rounding-mode,decimal-default-scale… 15 casa me parece bem justo já, mais que isso dá uns erros no Java.
Com o catálogo pronto é possível fazer o deploy com docker-compose…
version: "3.3"
services:
############
# Metabase #
test-db-metabase:
image: postgres:15
environment:
- POSTGRES_PASSWORD=metabase
- POSTGRES_USER=metabase
- POSTGRES_DB=metabase
metabase-app:
image: docker.io/andrebaceti/metabase-pumpwood:v0.47.6
ports:
- 3000:3000
environment:
- MB_SITE_URL=http://0.0.0.0/8080/metabase
- MB_DB_TYPE=postgres
- MB_DB_DBNAME=metabase
- MB_DB_PORT=5432
- MB_DB_USER=metabase
- MB_DB_PASS=metabase
- MB_DB_HOST=test-db-metabase
- MB_EMBEDDING_SECRET_KEY=
- MB_ENCRYPTION_SECRET_KEY=
##################
# Trino database #
test-db-hive-metastore:
image: $TEST_REPO/test-db-hive-metastore:$TEST_DB_HIVE_METASTORE
restart: always
ports:
- 9956:5432
hive-metastore-app:
container_name: hive-metastore-app
image: docker.io/andrebaceti/hive-metastore-pumpwood:0.2.10
user: "hive:hive"
volumes:
- test-bucket-config:/etc/secrets/
trino-coordinator:
container_name: trino-coordinator
image: docker.io/andrebaceti/trino-coordinator:430-1.1
volumes:
- ./catalog.zip:/catalog/catalog.zip
- test-bucket-config:/etc/secrets/
trino-worker:
image: docker.io/andrebaceti/trino-worker:430-1.1
volumes:
- ./catalog.zip:/catalog/catalog.zip
- test-bucket-config:/etc/secrets/
deploy:
replicas: 3
#####################
# Auth Microservice #
test-db-pumpwood-auth:
image: $TEST_REPO/test-db-pumpwood-auth:$TEST_DB_PUMPWOOD_AUTH
#########################
# Datalake Microservice #
test-db-pumpwood-datalake:
image: $TEST_REPO/test-db-pumpwood-datalake:$TEST_DB_PUMPWOOD_DATALAKE
volumes:
test-bucket-config:
external: trueNo exemplo acima estamos fazendo o deploy dentro do docker-compose de duas bases de dados Postgres, um Hive metastore que é utilizados pelo Trino para fazer as query nos arquivos do GCP e um metabase. Verifique que o único serviço exposto para fora do docker-compose é o metabase, mas o metabase tem acesso ao Trino e demais bancos que estão dentro do compose. Dessa forma é possível usar o metabase para construir relatórios com o Trino como um datamesh (não sei se é esse o termo correto nesse caso) para demais bancos de dados, aumentando performance e permitindo a integração dos dados sem a necessidade de expor nenhum deles para fora da rede do docker-compose.
Acho que é isso, deu um bom trabalho por esse trem em pé, mas deu orgulho depois.
See you space rabbits, someday, someproject…